An overview of Mozilla’s Data Pipeline
This post describes the architecture of Mozilla’s data pipeline, which is used to collect Telemetry data from our products and logs from various services.
The bulk of the data handled by this pipeline is Firefox Telemetry data, but the same tool-chain is used to collect, store, and analyze data coming from many sources, including Glean applications.
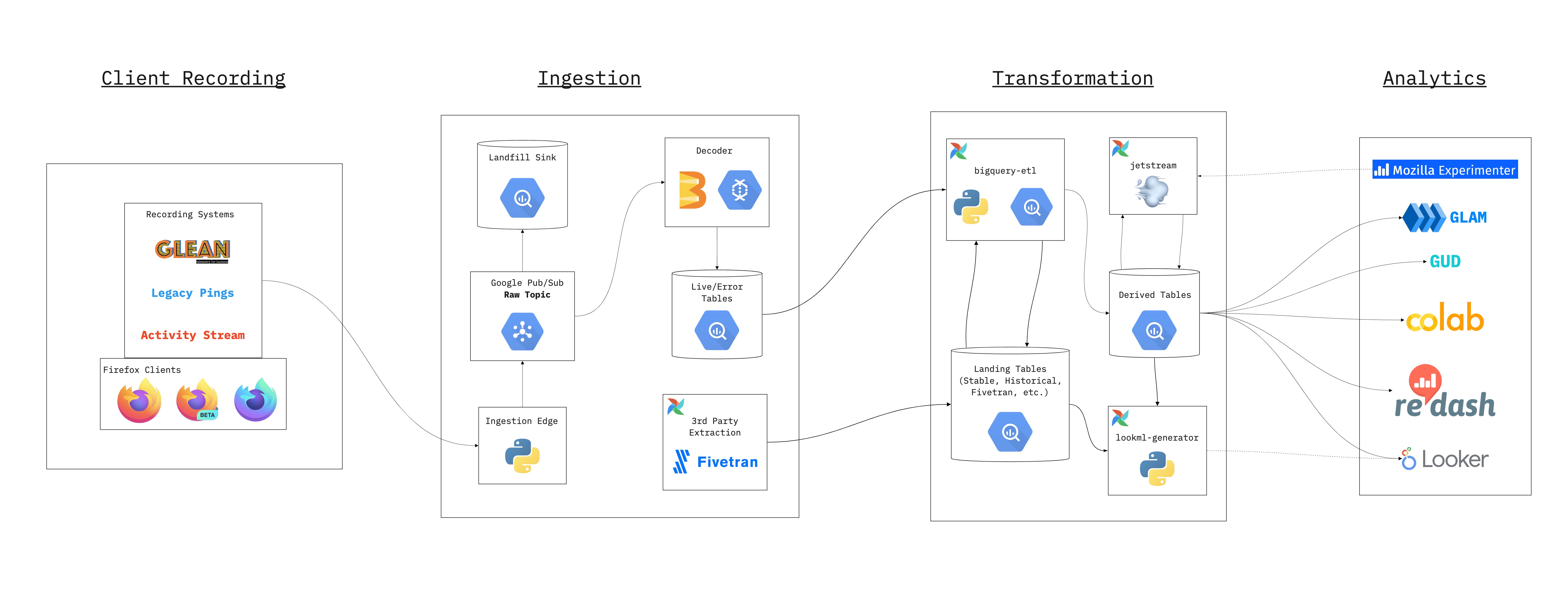
Here is a simplified diagram of how data is ingested into the data warehouse.
The code for the ingestion pipeline lives in the gcp-ingestion repository.
graph TD f1(fa:fa-firefox Firefox) -->|HTTP Post| d0(fa:fa-filter Ingestion Edge) d0 --> p1(fa:fa-stream Raw Topic) p1 --> d1(fa:fa-exchange-alt Landfill Sink) d1 --> b1(fa:fa-database Landfill BQ) p1 --> d2(fa:fa-exchange-alt Decoder) d2 -->|success| p2(fa:fa-stream Decoded Topic) d2 -.->|fail| p3(fa:fa-stream Errors Topic) p3 --> d4(fa:fa-exchange-alt Errors Sink) p2 --> d3(fa:fa-exchange-alt BigQuery Sink) d3 --> b2(fa:fa-database Live Tables BQ) d4 --> b3(fa:fa-database Error Tables BQ) classDef pubsub fill:#eff,stroke:#099; classDef exec fill:#efe,stroke:#090; classDef producers fill:#fee,stroke:#f90; classDef bq fill:#ececff,stroke:#9370db; class p1,p2,p3 pubsub class d0,d1,d2,d3,d4 exec class f1 producers class b1,b2,b3 bq
Firefox
There are different APIs and formats to collect data in Firefox, all suiting different use cases:
- histograms – for recording multiple data points;
- scalars – for recording single values;
- timings – for measuring how long operations take;
- events – for recording time-stamped events.
These are commonly referred to as probes. Each probe must declare the collection policy it conforms to: either release or prerelease. When adding a new measurement data-reviewers carefully inspect the probe and eventually approve the requested collection policy:
- Release data is collected from all Firefox users.
- Prerelease data is collected from users on Firefox Nightly and Beta channels.
Users may choose to turn the data collection off in preferences.
A session begins when Firefox starts up and ends when it shuts down.
As a session could be long-running and last weeks, it gets sliced into
smaller logical units called subsessions.
Each subsession generates a batch of data containing the current state
of all probes collected so far, in the form of a [main ping], which is
sent to our servers.
The main ping is just one of the many ping types we support.
Developers can create their own ping types if needed.
Pings are submitted via an API that performs a HTTP POST request to our edge servers. If a ping fails to successfully submit (e.g. because of missing internet connection), Firefox will store the ping on disk and retry to send it until the maximum ping age is exceeded.
Ingestion
Submissions coming in from the wild hit a load balancer and then an HTTP Server that accepts POST requests containing a message body of optionally-gzipped JSON.
These messages are forwarded to a PubSub message queue with minimal processing, and made available in a Raw topic.
A Dataflow job reads this topic and writes the raw messages to a BigQuery Landfill sink. This Landfill data is not used for analysis, but is stored in its raw form for recovery and backfill purposes.
If there is a processing error or data-loss downstream in the pipeline, this is an important fail-safe.
Decoding
Once the raw data has been added to the PubSub queue, it's time to process it.
The decoder is implemented as a Dataflow job, and is written in Java.
The decoding process tackles decompression, parsing, validation, deduplication, and enrichment of incoming messages.
After a message is decompressed and parsed as JSON, we apply JSONSchema validation to ensure that submissions are well-formed.
Sometimes duplicate submissions are sent to the pipeline, either due to normal networking failures or weird behaviour out there in the world. We watch for duplicate submissions, and discard any subsequent occurrences of already-seen records.
Submissions are also enriched with some metadata about the request itself, including things like HTTP headers, GeoIP information, and submission timestamp.
Messages that pass successfully through all these steps are written to another PubSub Decoded topic.
A failure in any of these steps results in messages being sent to the Errors sink. This separates invalid data from valid data, while still making it available for monitoring and debugging. This is a good way to keep an eye on the health of the pipeline and the data flowing through.
Data Warehouse
Decoded data is ultimately written out to BigQuery, which acts as the data warehouse.
By this time, incoming data has already been validated against the corresponding
JSONSchema specification for each document type.
Part of the decoding process above transforms this JSON structure into something
more easily represented in BigQuery.
One important transformation here is to convert all incoming fields from
UPPER CASE or camelCase to snake_case.
Another important transformation is to incorporate metadata about known probes
and metrics to generate more complete schemas.
This is handled by a combination of the decoder above, the schema transpiler and the schema generator. The result are tables that contains SQL-friendly field names for all known measures, as implemented in the probe scraper.
A Dataflow job reads from the Decoded topic and writes out to live ping tables. These tables are updated frequently, and typically reflect data within a few minutes of it being ingested. They are optimized for accessing recent data, but are only guaranteed to contain a few days of history.
Historical raw ping data is stored in historical ping tables,
also known as stable tables.
These tables include only completed days of data, are populated once a day
shortly after midnight UTC.
Data in the Stable tables is partitioned by day, and optimized for accessing
larger time periods. It is also optimized for limiting analysis to a fraction
of the data using the normalized_channel and sample_id fields.
Beyond the Data Warehouse
The diagram above shows the path data takes to get into the data warehouse. After that, we have to start using it!
Workflow Management and ETL
We use Airflow for workflow management.
It orchestrates the daily creation of the Stable tables described above, as well as many other derived datasets.
The ETL code to create derived datasets is commonly implemented using queries in BigQuery.
Many examples can be found in the bigquery-etl repository.
Data in BigQuery is also accessible via Spark, and several ETL jobs also run via Dataproc.
These jobs produce data sets that are used for downstream analysis and data applications (such as measurement, addon recommendation, and other data products).
Data Analysis
Once the data reaches our data warehouse in BigQuery it can be processed in a number of ways as described in the Accessing BigQuery article.
Data analysis is most commonly done using Looker or using SQL queries.
In summary, the following diagram illustrates how Recording, Ingestion, Transformation, Scheduling and Analytics fit together:
Handling Sensitive Data
Some data is more sensitive than others and introduces more risk around how it is handled. We characterize sensitivity of data broadly into four categories as described on the Data Collection wiki page.
Sensitive data — by which we mean category 3 and 4 data — increases the level of risk and so warrants extra care. For such data, we apply three main mitigation measures:
Limited access Access to sensitive data is limited to individuals or groups with clearly articulated need. Access is also limited in time, so access expires by default.
Limited retention Sensitive data is kept for a finite period of time after which it is automatically deleted. For example, data containing search terms is only kept for a short period of time.
Sanitization and aggregation of data Where data has the potential to be personally identifiable, we have best effort (and improving over time) ETL jobs that scrub incoming data of potentially identifying information, which reduces risk. When possible, we build and work with aggregate datasets rather than individual-level data.